When it comes to graphics, things sure have changed since the beginning of the project. Back in the day — almost 20 (!) years ago — GPUs were relatively slow, you had a few MBs of VRAM, and screen resolutions were in the 1K range. Nowadays most of these metrics have grown by an order of magnitude or two and the optimal way of using the GPU has changed. While CPUs have gotten significantly faster over the years, GPU performance has dramatically increased in vast leaps and bounds. Today, a renderer needs to be designed around feeding the GPU and allowing it do its thing as independently as possible.
With so much computation power available, rendering techniques and algorithms are allowed to be much more complex. However, Doomsday’s needs are pretty specific — what is the correct approach to take here? During the spring I’ve been exploring the possibilities and potential directions that a completely redesigned renderer could take. In this post, I’ll share some of the results and related thoughts about where things could and should be heading.
Vertex-shaded world
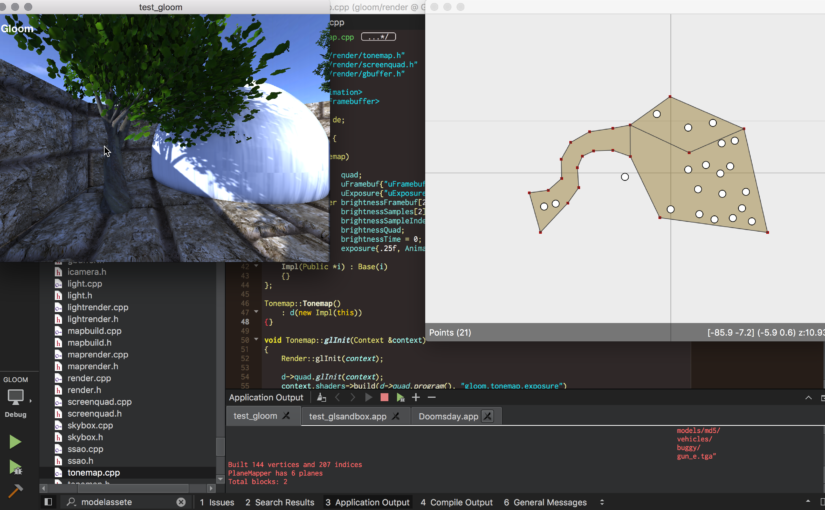
One of the interesting aspects of the first-generation DOOM engine is that all floors and ceilings (i.e., planes) are allowed to dynamically move up and down at any time. This is due to the 2D nature of the map — the vertical dimension is left unspecified until the world is actually rendered.
In the past, Doomsday has resorted to pushing all new vertex data on every frame to account for this dynamic nature of the world. Combined with robust clipping of visible geometry, this has been mostly an acceptable solution, although it puts all the burden on the CPU to determine which surfaces are actually drawn. Thankfully most maps have only a small number of vertices and triangles so not too much data has been flowing around.
One of the ideas that I’ve found fascinating in recent years is the procedural augmentation of map geometry using 3D meshes. This is analogous to the idea of light source decorations, where lights can be attached to certain pixel offsets on textures. However, the end result is that surface geometry will have a lot more vertices. It will not do to keep streaming all of it dynamically.
There are basically two solutions here: static vertex data accompanied by a buffer of vertical offsets, and instanced mesh rendering. What I’ve implemented so far is that a static, read-only version of the entire map geometry is copied to one buffer, and there is another (much smaller) dynamic buffer containing “plane heights” that get applied to vertex positions in the vertex shader. All vertices connected to a certain plane use the same plane height value, allowing all of them to move by modifying a single value in the vertical offsets buffer.
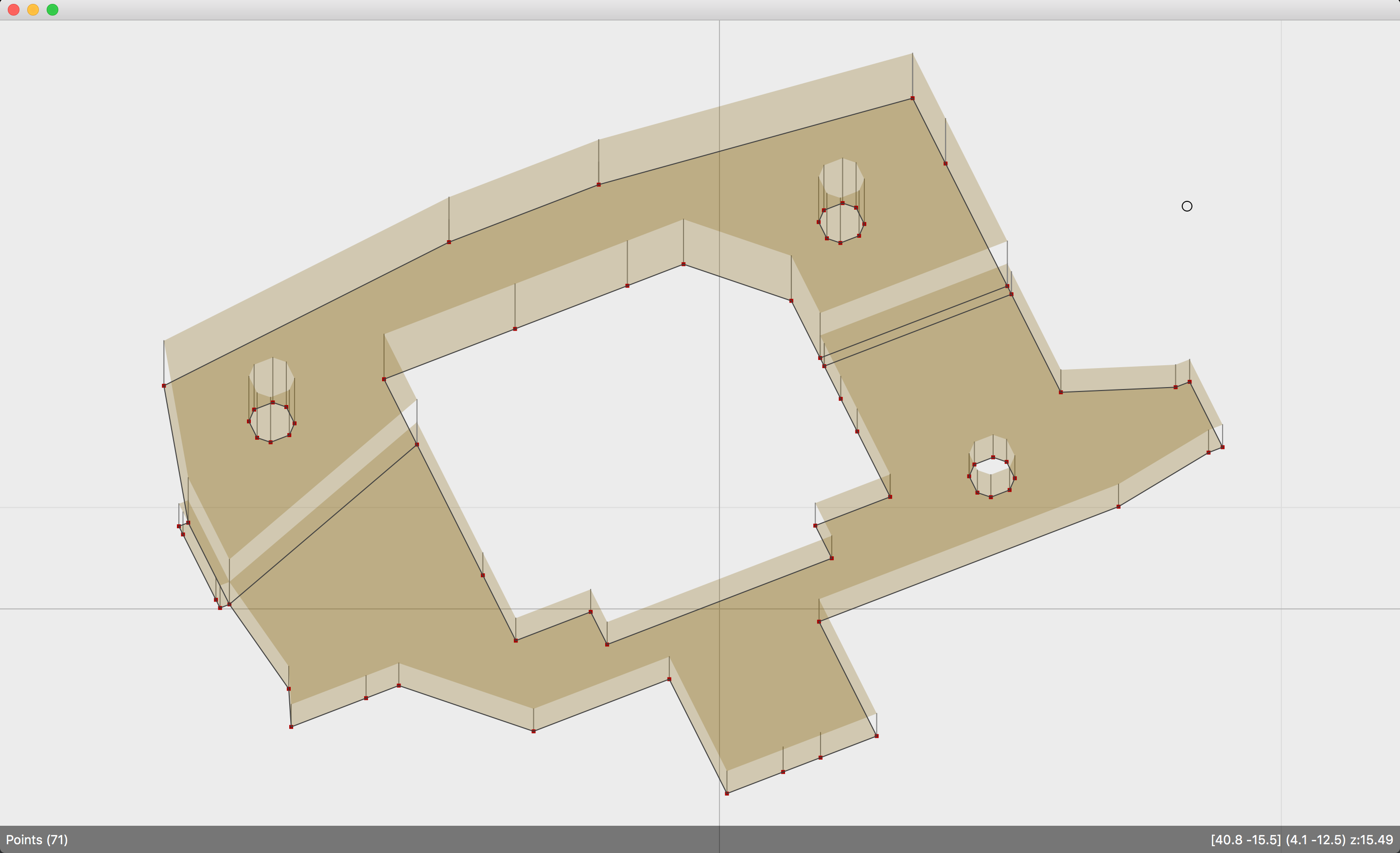
On the other hand, mesh instances are good for repeating the same 3D shapes multiple times. Considering that Doom textures are pretty small and thus repeat multiple times over longer surface, 3D decorations can efficiently be rendered as instances. (So far I haven’t actually implemented this.)
There are some interesting side effects to having a single mesh represent a level where floors and ceilings can move arbitrarily. For example, consider the bottom/top section of a wall connecting two floors/ceilings. Depending on which floor/ceiling is higher at a given time, the section of the wall may be facing either the front or back sector of the line. Because the map data remains static in GPU memory and the plane heights can change dynamically, this means both sides of the line must be stored in the vertex data, and the vertex shader needs to determine which side is currently visible.
G-buffer and SSAO
Advanced rendering techniques need a lot more information than one can store in a simple 24-bit RGB framebuffer, like the one used in the Doomsday 1.x (D1) renderer. The basic principle is that instead of directly rendering to visible RGB colors, there are one or more intermediate steps where various kinds of buffers are rendered first, and then subsequent rendering passes can use this cached data to compute the actual visible colors.
In practice, I’m talking about using a “G-buffer” and a separate 16-bit floating point RGB frame buffer. The G-buffer contains depth values, normal vectors, surface albedo colors, material specular/gloss parameters, and emissive lighting values. The benefit of floating-point color is that one can sum up the results of all the intermediate shading steps and end up with a physically accurate representation of total surface lighting.
After setting up the G-buffer, the first effect I implemented was classic screen-space ambient occlusion. It is based on sampling the neighborhood of each pixel to estimate how much ambient light arriving at the pixel gets occluded. This requires access to per-pixel depth values and normal vectors, which are provided by the G-buffer. While the technique is relatively simple, tuning it to produce exactly the right appearance for Doom maps will be the main challenge. In the end, it should be able to to replicate an effect similar to the old textured triangle-based corner shadows that Doomsday has been using in the past — however with much more fidelity and the effect will apply to all meshes including objects. The old triangle-based shadowing is also quite a lot of not-that-straightforward code that will be good to retire. This will also make it unnecessary to render any kind of additional “shadow blobs” under objects, as these will be automatically produced by the SSAO pass.

Deferred shading
There are essentially two kinds of light sources in Doom maps: point lights (usually attached to objects), and volume lighting (bright sectors). The former translates pretty easily to GPU-based shading, but the latter will require more effort. If one simply takes the old sector boundaries and uses those for lighting objects and surfaces, the result won’t be terribly convincing.
I’ve been thinking about higher-fidelity global illumination approaches but haven’t prototyped one yet. The closest analogy in the D1 renderer is the “bias lighting grid”, which was essentially trying to solve the same problem. However, it was always limited to vertex-based lighting so it had trouble working in spacious/low-poly rooms. It was also updated entirely on the CPU, making it pretty inefficient. Modern GPUs have the capability to construct and update a more complex global illumination data structure on the fly; I intend to explore this direction further in the future.
With the G-buffer providing information about visible pixels in the frame, lighting can be done as a separate rendering pass that affects only the visible pixels. This kind of deferred shading is suitable especially when the scene contains many light sources.
It is interesting to note that this has some similarities to the way the D1 renderer draws dynamic lights. (Setting aside that D1 does not do any kind of per-pixel lighting calculations since it does not use shaders on world surfaces.) While a small number of lights is drawn in a single pass (light textures multiplied with the surface color), additional lights are applied during a separate rendering pass where each dynamic light is represented by quads projected on surfaces. The D1 renderer needs to first project all dynamic lights to walls and planes using the CPU to generate a set of contact quads; in the new renderer, the corresponding operation occurs fully on the GPU using stencils and without assumptions about the shape of the world.
Shadow maps
The D1 renderer hasn’t done much in the area of shadows even though there have been positional light sources since the beginning. Rendering shadows requires quickly drawing the world a few times from different points of view, and this has not been feasible due to the aforementioned inefficient way of handling map geometry.
Good-quality shadows are absolutely essential for creating convincing visuals, so they are an important feature to have in the future. I’ve been looking at two types of shadow maps: basic directional ones for bright outdoors lighting, and cubic shadows for point lights.

Now that I have the world geometry in static form in GPU memory, it is possible to render multiple shadow passes to generate a set of shadow maps. One of the tricky parts here is choosing which lights will cast shadows in the frame — each shadow map takes up rendering time and memory, and a typical map might have dozens or even hundreds of light sources. Cubic shadow maps also a bit more expensive to update as they need to be rendered using six different viewing directions.
Remaining work here is to implement cascaded shadow maps to improve the quality of directional shadows.
To be continued…
There is a lot more to cover so this will be a series of posts. In the next part, I’ll discuss HDR rendering, PBR materials, and liquids.